
こんにちんは、もがちゃんです。
今回は、C言語で簡単な関数をテストファーストで開発してみたいと思います。
目次
使用する開発環境は
今回の開発で使用する環境は以下の通りです。
- Windows10
- Eclipse Version: 2020-06(Pleiades All in One Eclipse Windows 64bit C/C++ Full Edition)
- cpputest-3.8
- CppUtest Test Runner
以前の記事で、cpputest-3.8とCppUtest Test Runnerの設定は行っているので、まだ設定を行っていない人は、以下の記事を参照して設定を行ってください。
テストファーストで開発する前に
テストファーストで開発する前にEclipse上で使用するプロジェクトを作成して、CppUtestが使用できるように設定が必要になります。
Eclipse上にプロジェクトを作成する方法は、以下の通りです。
メニューからファイル(F) ⇒ 新規(N) ⇒ プロジェクト(R)を選ぶ
新規プロジェクトダイアログから、C/C++のC++プロジェクトを選び、「次へ(N)>」をクリック
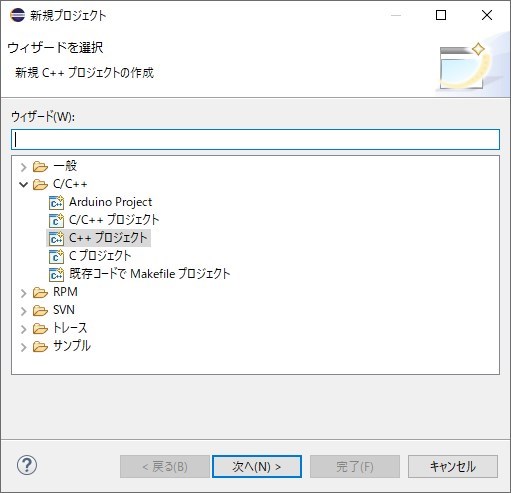
C++プロジェクトダイアログで、任意のプロジェクト名を入力
プロジェクトタイプから実行可能>空のプロジェクトを選択
ツールチェーンからMinGW GCCを選択し、「完了(F)」をクリック
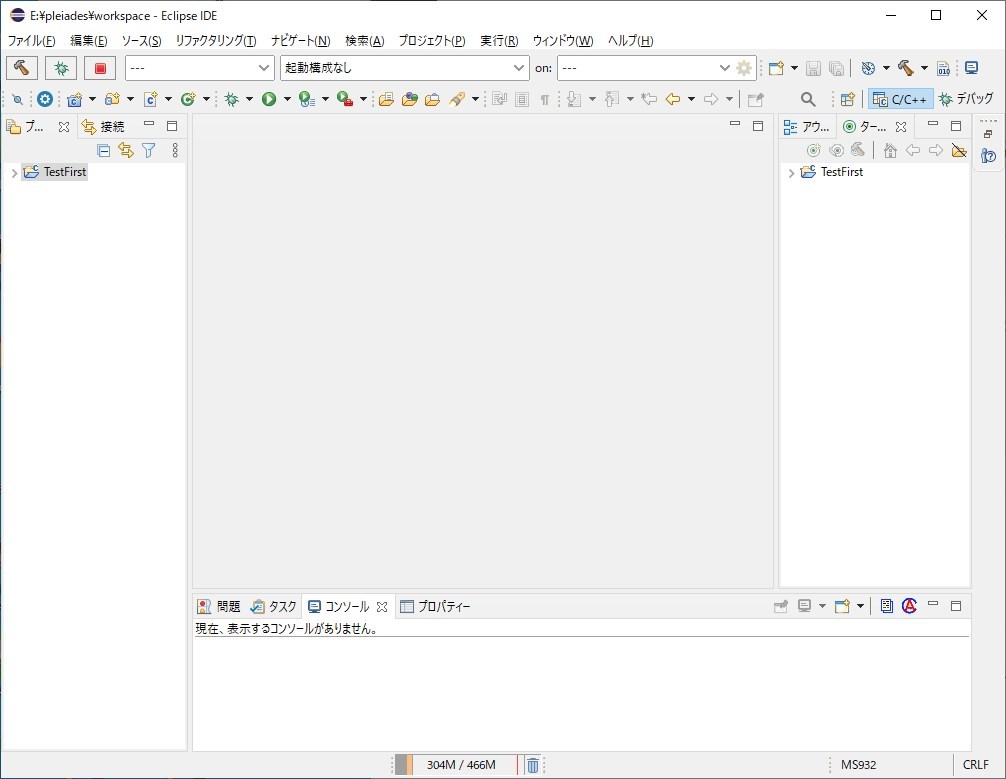
Eclipse上に作成したプロジェクトに設定する項目は、以下の項目です。
- CppUtestのヘッダのパス
- CppUtestのライブラリ
- CppUtestのライブラリのパス
各々の設定する場所と設定値を以下にまとめました。
設定値は、メニューからプロジェクト(P) ⇒ プロパティでプロジェクトのプロパティダイアログを表示して設定します。
CppUtestのヘッダのパスは、C/C++ 一般 > パスおよびシンボル > インクルードタブに設定します。
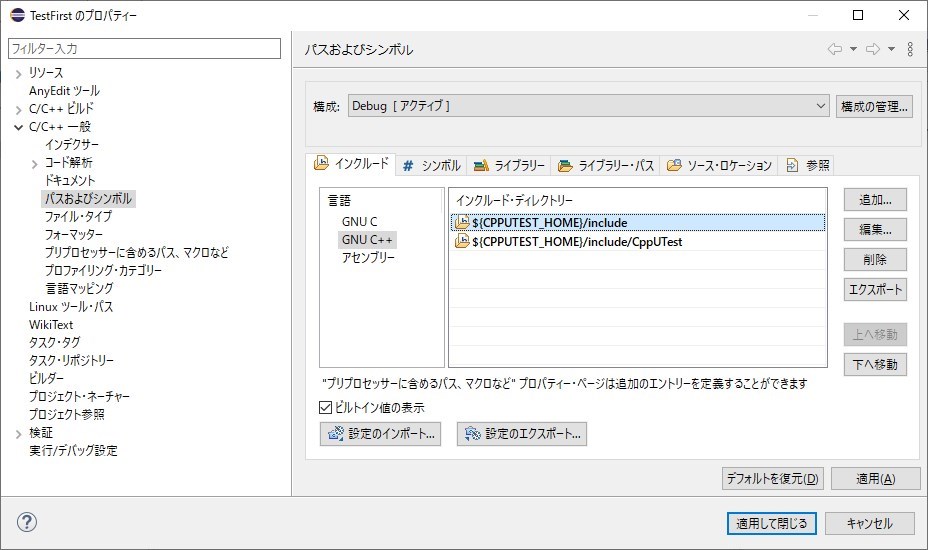
${CPPUTEST_HOME}/include
${CPPUTEST_HOME}/include/CppUTest続いてライブラリータブにCppUtestのライブラリを設定します。
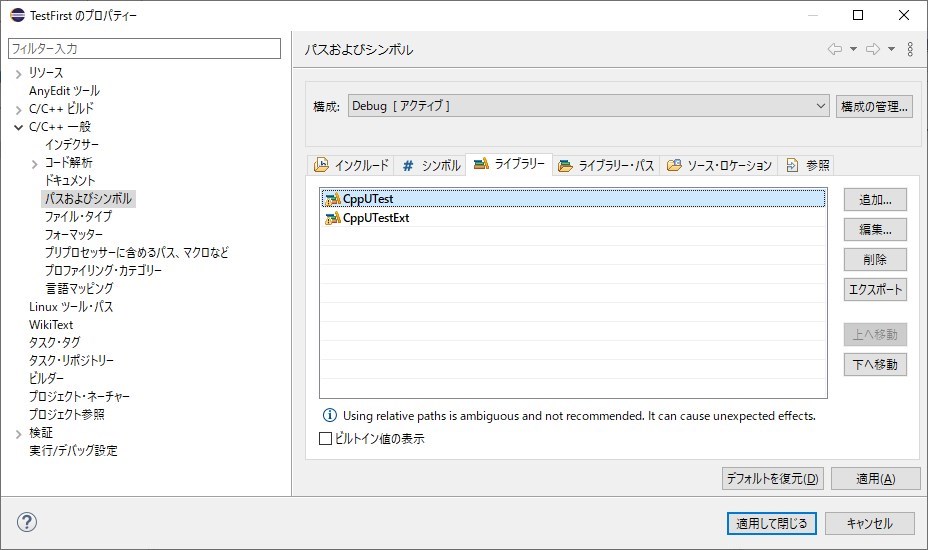
CppUTest
CppUTestExt最後にCppUtestのライブラリのパスをライブラリー・パスタブに設定し、「適用して閉じる」をクリックします。
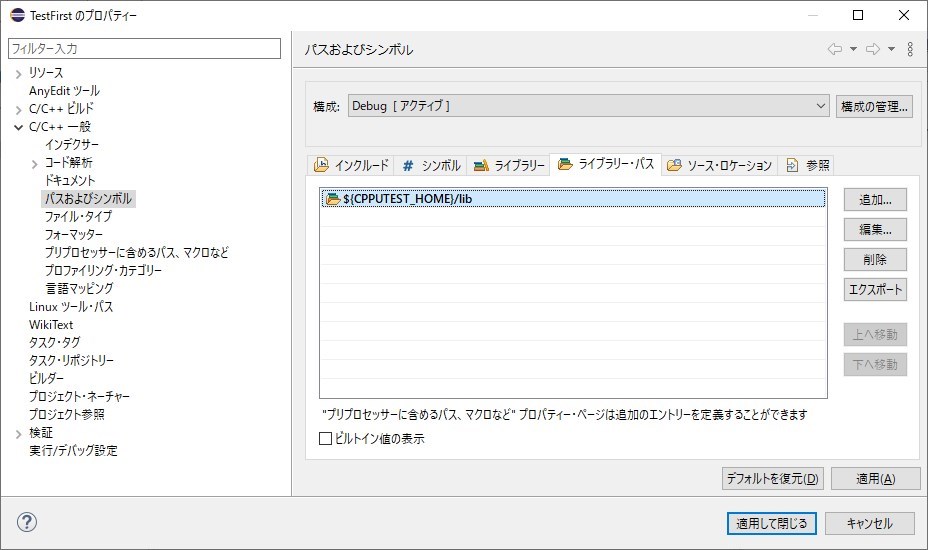
${CPPUTEST_HOME}/lib以上でテストファーストで開発する準備ができました。
C言語の開発なので、プロジェクトもCプロジェクトを使用すればいいじゃんって思うと思いますが、テストファーストで開発するにあたり、CppUtestを使用するためにC++プロジェクトを使用します。
今回開発したい関数は
今回テストファーストで開発したい関数は、指定した文字列を指定した文字で分割した結果を返す関数を開発してみたいと思います。(VBScriptなどにあるSplit関数のようなもの)
関数の定義
char** split(const char *splitStr, const char splitChar)
引数
splitStrには、分割対象となる文字列のポインタを指定する。
splitCharには、分割に使用する文字を指定する。
返却値
分割した各文字列のポインタが格納されているポインタ、終端はNULLを設定する。
制限
対象とする文字列は、ASCII文字のみ(特にチェック等はしない)
splitStrで指定できる最大の文字列長は、30バイト(特にチェック等はしない、30バイトまでしか処理対象としない)
今回開発したい関数のソースを以下のように作成しました。(処理の実装はしていない状態)
#ifdef __cplusplus
extern "C" {
extern char** split(const char *splitStr, const char splitChar);
}
#endif // __cplusplus
/*
* split.c
*
* Created on: 2020/08/29
*/
#include <stdio.h>
#include "split.h"
char** split(const char *splitStr, const char splitChar) {
return NULL;
}
テストを書いてみる
今回テストする内容を以下の4つを考えて作成してみる。
- splitStrにNULLを指定した時
返却値はNULL。(返却値 == NULL) - splitStrに空文字(長さ0の文字)を指定した時
返却値[0]は、空文字(長さ0の文字)
返却値[1]は、NULL。 - splitStrに”123456″を指定して、splitCharに半角スペースを指定した時
返却値[0]は、文字列”123456″へのポインタ
返却値[1]は、NULL - splitStrに”1234567890abcdef0ABCDEFG012abcefg”を指定して、splitCharに’0’を指定した時
返却値[0]は、文字列”123456789″へのポインタ
返却値[1]は、文字列”abcdef”へのポインタ
返却値[2]は、文字列”ABCDEFG”へのポインタ
返却値[3]は、文字列”12abc”へのポインタ
返却値[4]は、NULL
作成したソース(AllTests.cppとsplitTest.cpp)が以下になります。
/*
* AllTests.cpp
*
* Created on: 2020/08/29
*/
#include "CppUTest/CommandLineTestRunner.h"
int main(int argc, char *argv[]) {
return CommandLineTestRunner::RunAllTests(argc, argv);
}
/*
* splitTest.cpp
*
* Created on: 2020/08/29
*/
#include "CppUTest/TestHarness.h"
#include <string.h>
#include "split.h"
TEST_GROUP(Split) {
};
/**
* テスト項目1
*/
TEST(Split, Test1) {
char** ret = split(NULL, ' ');
CHECK(ret == NULL);
}
/**
* テスト項目2
*/
TEST(Split, Test2) {
char** ret = split("", ' ');
CHECK(ret != NULL);
CHECK(0 == strcmp(ret[0],""));
CHECK(ret[1] == NULL);
}
/**
* テスト項目3
*/
TEST(Split, Test3) {
char** ret = split("123456", ' ');
CHECK(ret != NULL);
CHECK(0 == strcmp(ret[0],"123456"));
CHECK(ret[1] == NULL);
}
/**
* テスト項目4
*/
TEST(Split, Test4) {
char** ret = split("1234567890abcdef0ABCDEFG012abcefg", '0');
CHECK(ret != NULL);
CHECK(0 == strcmp(ret[0],"123456789"));
CHECK(0 == strcmp(ret[1],"abcdef"));
CHECK(0 == strcmp(ret[2],"ABCDEFG"));
CHECK(0 == strcmp(ret[3],"12abc"));
CHECK(ret[4] == NULL);
}
CppUtest Test Runnerでテストを実行してみる
ソースのビルドが成功し、CppUtest Test Runnerでテストを実行するには、以下のようにして実行します。
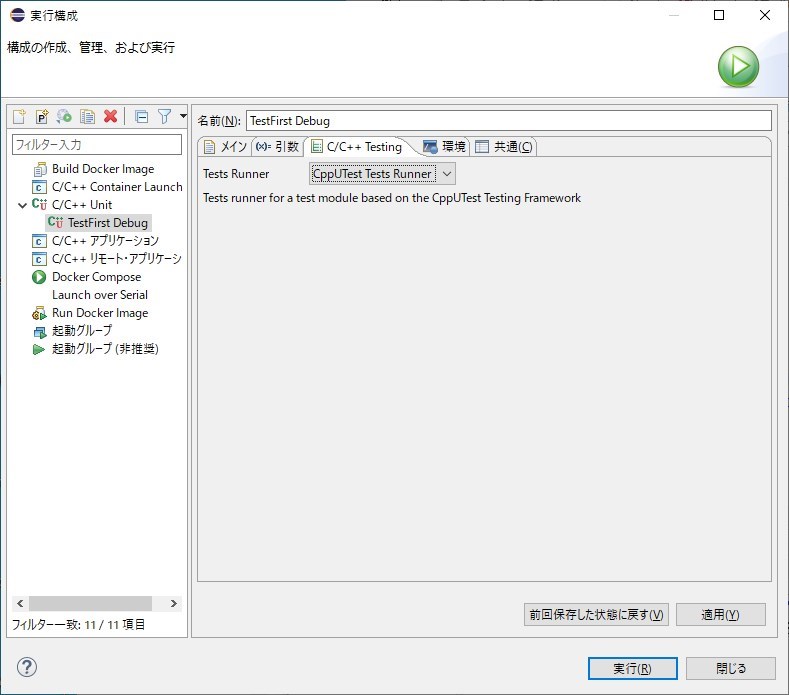
メニューの実行(R) ⇒ 実行構成(N)で実行構成ダイアログを表示します。
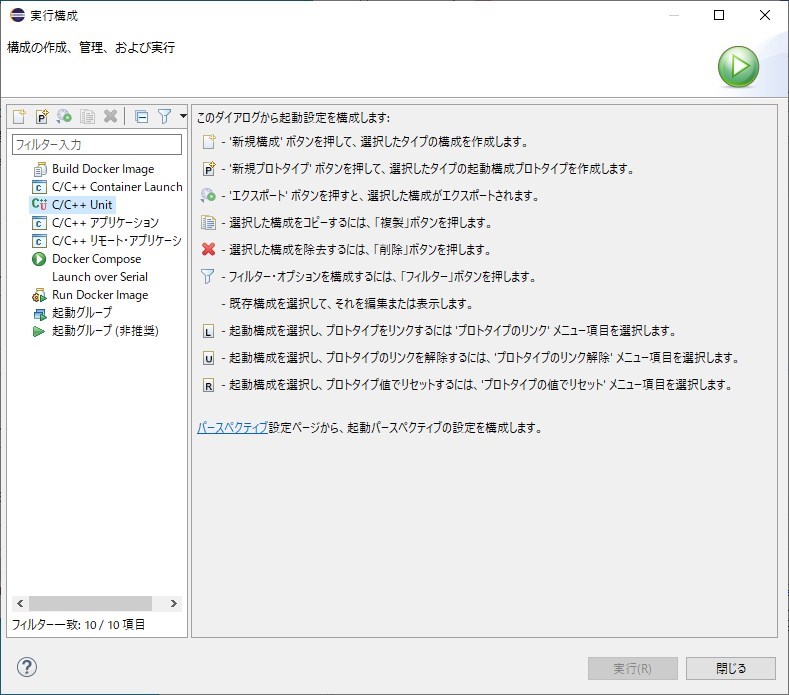
C/C++ Unitをダブルクリックして実行構成を追加し、設定を行う。
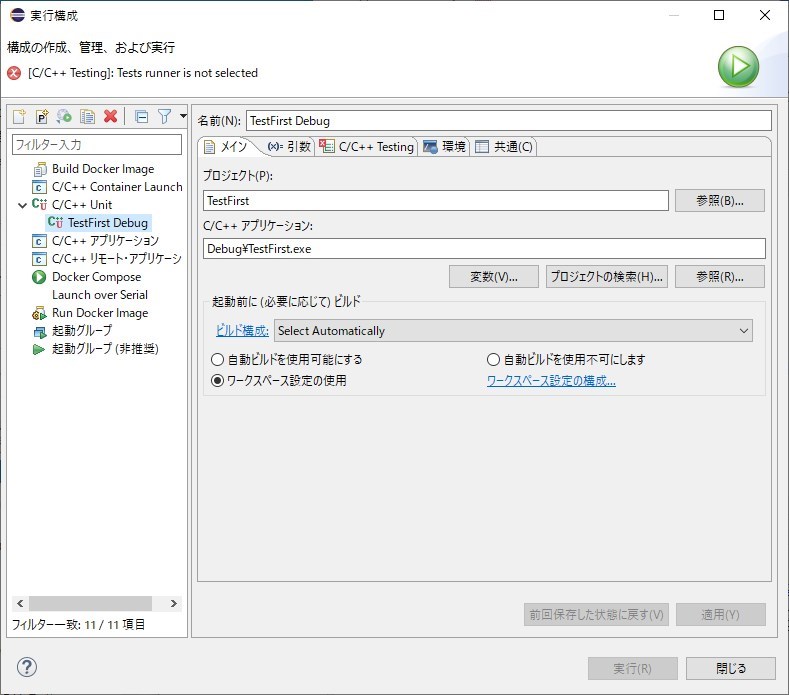
C/C++ Testingタブで使用するTests Runnerを設定する。
今回使用するのは、CppUtest Test RunnerなのでCppUTest Tests Runnerを選択し、「適用(Y)」「閉じる」を順にクリックする。(「閉じる」の代わりに「実行(R)」でもOK)
「実行」もしくは「デバッグ実行」する
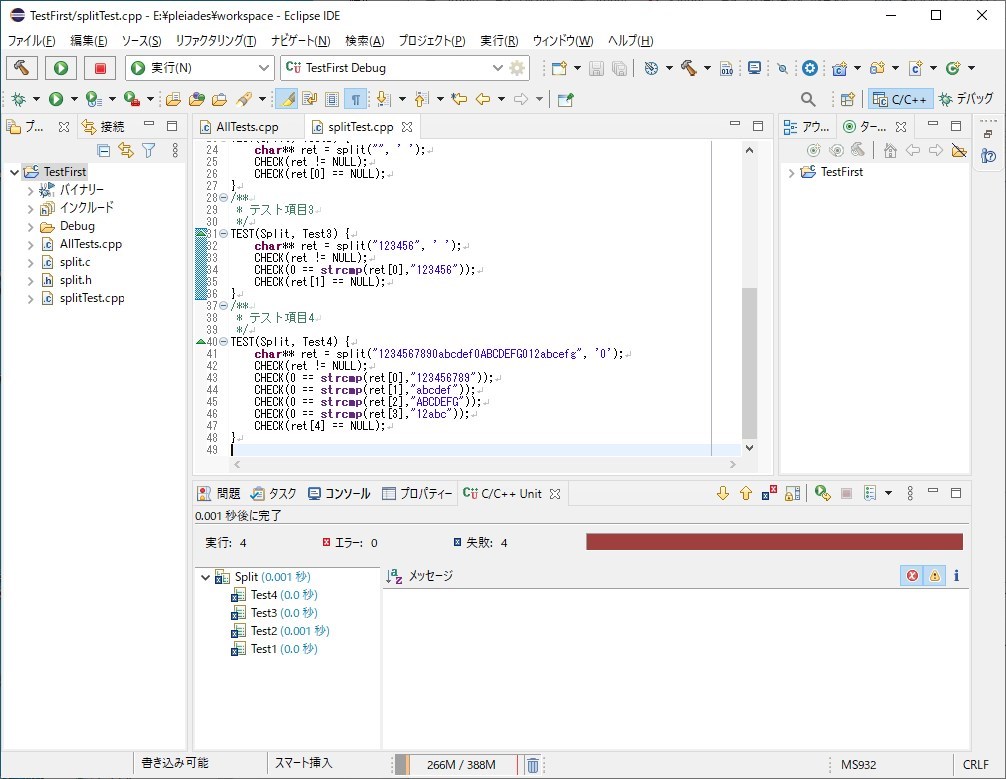
split関数の処理部分は作っていないので当然ながら全てのテストが失敗しています。
あとは、このテストが全て成功するようにsplit関数の処理を実装していきます。
そして、全て成功したソースが以下のソースになります。
/*
* split.c
*
* Created on: 2020/08/29
*/
#include <stdio.h>
#include <string.h>
#include "split.h"
/*
* 指定された文字列を指定された分割文字で分割する
* 分割した結果の各分割文字列の先頭ポインタの配列を返却する。
* 返却する分割文字列ポインタの配列に終端としてNULLポインタを設定する。
*
* 関数名:split(文字列分割)
* 引数:const char *splitStr 分割対象文字列
* const char splitChar 分割文字
* 返却値:分割結果
* 分割後の各文字列の先頭ポインタを格納した配列
* 終端マークとしてNULLポインタを最後に格納
*
* 制限:
* ASCII文字のみ
* splitStrで指定された文字列の先頭から30文字分を分割対象とし
* 31バイト分以降は無視する(無いものとして扱う)
*
*/
char** split(const char *splitStr, const char splitChar) {
// 制限として 30バイト分としているので
// 最低30バイトの文字列入ればよい(余分に領域確保)
static char splitBuffer[64];
// 分割後の各文字列のポインタを格納する領域(余分に領域確保)
static char *pTable[64];
// splitBufferをクリア
memset(splitBuffer, '/*
* split.c
*
* Created on: 2020/08/29
*/
#include <stdio.h>
#include <string.h>
#include "split.h"
/*
* 指定された文字列を指定された分割文字で分割する
* 分割した結果の各分割文字列の先頭ポインタの配列を返却する。
* 返却する分割文字列ポインタの配列に終端としてNULLポインタを設定する。
*
* 関数名:split(文字列分割)
* 引数:const char *splitStr 分割対象文字列
* const char splitChar 分割文字
* 返却値:分割結果
* 分割後の各文字列の先頭ポインタを格納した配列
* 終端マークとしてNULLポインタを最後に格納
*
* 制限:
* ASCII文字のみ
* splitStrで指定された文字列の先頭から30文字分を分割対象とし
* 31バイト分以降は無視する(無いものとして扱う)
*
*/
char** split(const char *splitStr, const char splitChar) {
// 制限として 30バイト分としているので
// 最低30バイトの文字列入ればよい(余分に領域確保)
static char splitBuffer[64];
// 分割後の各文字列のポインタを格納する領域(余分に領域確保)
static char *pTable[64];
// splitBufferをクリア
memset(splitBuffer, '\0', sizeof(splitBuffer));
// pTableをクリア
memset(pTable, 0, sizeof(pTable));
// splitStr が NULL
if(NULL == splitStr) {
return NULL;
}
// splitBufferにsplitStrの文字列を最大30文字コピー
strncpy(splitBuffer, splitStr, 30);
int i = 0;
char *p = NULL;
pTable[i] = splitBuffer;
/*
* splitBufferの先頭からNULL文字が現れるまで
* 区切り文字が現れたら、NULL文字を設定し文字列を区切る
* 区切り文字の次が'\0'でなければ、pTableにアドレスを設定する
*/
for(p = splitBuffer, i = 0; *p != '\0'; p++) {
if(splitChar == *p) {
*p = '\0'; // 文字列を区切る
// 次が終端文字で無ければ、ポインタを設定
if(*(p+1) != '\0') {
pTable[++i] = p+1;
}
}
}
return pTable;
}
', sizeof(splitBuffer));
// pTableをクリア
memset(pTable, 0, sizeof(pTable));
// splitStr が NULL
if(NULL == splitStr) {
return NULL;
}
// splitBufferにsplitStrの文字列を最大30文字コピー
strncpy(splitBuffer, splitStr, 30);
int i = 0;
char *p = NULL;
pTable[i] = splitBuffer;
/*
* splitBufferの先頭からNULL文字が現れるまで
* 区切り文字が現れたら、NULL文字を設定し文字列を区切る
* 区切り文字の次が'/*
* split.c
*
* Created on: 2020/08/29
*/
#include <stdio.h>
#include <string.h>
#include "split.h"
/*
* 指定された文字列を指定された分割文字で分割する
* 分割した結果の各分割文字列の先頭ポインタの配列を返却する。
* 返却する分割文字列ポインタの配列に終端としてNULLポインタを設定する。
*
* 関数名:split(文字列分割)
* 引数:const char *splitStr 分割対象文字列
* const char splitChar 分割文字
* 返却値:分割結果
* 分割後の各文字列の先頭ポインタを格納した配列
* 終端マークとしてNULLポインタを最後に格納
*
* 制限:
* ASCII文字のみ
* splitStrで指定された文字列の先頭から30文字分を分割対象とし
* 31バイト分以降は無視する(無いものとして扱う)
*
*/
char** split(const char *splitStr, const char splitChar) {
// 制限として 30バイト分としているので
// 最低30バイトの文字列入ればよい(余分に領域確保)
static char splitBuffer[64];
// 分割後の各文字列のポインタを格納する領域(余分に領域確保)
static char *pTable[64];
// splitBufferをクリア
memset(splitBuffer, '\0', sizeof(splitBuffer));
// pTableをクリア
memset(pTable, 0, sizeof(pTable));
// splitStr が NULL
if(NULL == splitStr) {
return NULL;
}
// splitBufferにsplitStrの文字列を最大30文字コピー
strncpy(splitBuffer, splitStr, 30);
int i = 0;
char *p = NULL;
pTable[i] = splitBuffer;
/*
* splitBufferの先頭からNULL文字が現れるまで
* 区切り文字が現れたら、NULL文字を設定し文字列を区切る
* 区切り文字の次が'\0'でなければ、pTableにアドレスを設定する
*/
for(p = splitBuffer, i = 0; *p != '\0'; p++) {
if(splitChar == *p) {
*p = '\0'; // 文字列を区切る
// 次が終端文字で無ければ、ポインタを設定
if(*(p+1) != '\0') {
pTable[++i] = p+1;
}
}
}
return pTable;
}
'でなければ、pTableにアドレスを設定する
*/
for(p = splitBuffer, i = 0; *p != '/*
* split.c
*
* Created on: 2020/08/29
*/
#include <stdio.h>
#include <string.h>
#include "split.h"
/*
* 指定された文字列を指定された分割文字で分割する
* 分割した結果の各分割文字列の先頭ポインタの配列を返却する。
* 返却する分割文字列ポインタの配列に終端としてNULLポインタを設定する。
*
* 関数名:split(文字列分割)
* 引数:const char *splitStr 分割対象文字列
* const char splitChar 分割文字
* 返却値:分割結果
* 分割後の各文字列の先頭ポインタを格納した配列
* 終端マークとしてNULLポインタを最後に格納
*
* 制限:
* ASCII文字のみ
* splitStrで指定された文字列の先頭から30文字分を分割対象とし
* 31バイト分以降は無視する(無いものとして扱う)
*
*/
char** split(const char *splitStr, const char splitChar) {
// 制限として 30バイト分としているので
// 最低30バイトの文字列入ればよい(余分に領域確保)
static char splitBuffer[64];
// 分割後の各文字列のポインタを格納する領域(余分に領域確保)
static char *pTable[64];
// splitBufferをクリア
memset(splitBuffer, '\0', sizeof(splitBuffer));
// pTableをクリア
memset(pTable, 0, sizeof(pTable));
// splitStr が NULL
if(NULL == splitStr) {
return NULL;
}
// splitBufferにsplitStrの文字列を最大30文字コピー
strncpy(splitBuffer, splitStr, 30);
int i = 0;
char *p = NULL;
pTable[i] = splitBuffer;
/*
* splitBufferの先頭からNULL文字が現れるまで
* 区切り文字が現れたら、NULL文字を設定し文字列を区切る
* 区切り文字の次が'\0'でなければ、pTableにアドレスを設定する
*/
for(p = splitBuffer, i = 0; *p != '\0'; p++) {
if(splitChar == *p) {
*p = '\0'; // 文字列を区切る
// 次が終端文字で無ければ、ポインタを設定
if(*(p+1) != '\0') {
pTable[++i] = p+1;
}
}
}
return pTable;
}
'; p++) {
if(splitChar == *p) {
*p = '/*
* split.c
*
* Created on: 2020/08/29
*/
#include <stdio.h>
#include <string.h>
#include "split.h"
/*
* 指定された文字列を指定された分割文字で分割する
* 分割した結果の各分割文字列の先頭ポインタの配列を返却する。
* 返却する分割文字列ポインタの配列に終端としてNULLポインタを設定する。
*
* 関数名:split(文字列分割)
* 引数:const char *splitStr 分割対象文字列
* const char splitChar 分割文字
* 返却値:分割結果
* 分割後の各文字列の先頭ポインタを格納した配列
* 終端マークとしてNULLポインタを最後に格納
*
* 制限:
* ASCII文字のみ
* splitStrで指定された文字列の先頭から30文字分を分割対象とし
* 31バイト分以降は無視する(無いものとして扱う)
*
*/
char** split(const char *splitStr, const char splitChar) {
// 制限として 30バイト分としているので
// 最低30バイトの文字列入ればよい(余分に領域確保)
static char splitBuffer[64];
// 分割後の各文字列のポインタを格納する領域(余分に領域確保)
static char *pTable[64];
// splitBufferをクリア
memset(splitBuffer, '\0', sizeof(splitBuffer));
// pTableをクリア
memset(pTable, 0, sizeof(pTable));
// splitStr が NULL
if(NULL == splitStr) {
return NULL;
}
// splitBufferにsplitStrの文字列を最大30文字コピー
strncpy(splitBuffer, splitStr, 30);
int i = 0;
char *p = NULL;
pTable[i] = splitBuffer;
/*
* splitBufferの先頭からNULL文字が現れるまで
* 区切り文字が現れたら、NULL文字を設定し文字列を区切る
* 区切り文字の次が'\0'でなければ、pTableにアドレスを設定する
*/
for(p = splitBuffer, i = 0; *p != '\0'; p++) {
if(splitChar == *p) {
*p = '\0'; // 文字列を区切る
// 次が終端文字で無ければ、ポインタを設定
if(*(p+1) != '\0') {
pTable[++i] = p+1;
}
}
}
return pTable;
}
'; // 文字列を区切る
// 次が終端文字で無ければ、ポインタを設定
if(*(p+1) != '/*
* split.c
*
* Created on: 2020/08/29
*/
#include <stdio.h>
#include <string.h>
#include "split.h"
/*
* 指定された文字列を指定された分割文字で分割する
* 分割した結果の各分割文字列の先頭ポインタの配列を返却する。
* 返却する分割文字列ポインタの配列に終端としてNULLポインタを設定する。
*
* 関数名:split(文字列分割)
* 引数:const char *splitStr 分割対象文字列
* const char splitChar 分割文字
* 返却値:分割結果
* 分割後の各文字列の先頭ポインタを格納した配列
* 終端マークとしてNULLポインタを最後に格納
*
* 制限:
* ASCII文字のみ
* splitStrで指定された文字列の先頭から30文字分を分割対象とし
* 31バイト分以降は無視する(無いものとして扱う)
*
*/
char** split(const char *splitStr, const char splitChar) {
// 制限として 30バイト分としているので
// 最低30バイトの文字列入ればよい(余分に領域確保)
static char splitBuffer[64];
// 分割後の各文字列のポインタを格納する領域(余分に領域確保)
static char *pTable[64];
// splitBufferをクリア
memset(splitBuffer, '\0', sizeof(splitBuffer));
// pTableをクリア
memset(pTable, 0, sizeof(pTable));
// splitStr が NULL
if(NULL == splitStr) {
return NULL;
}
// splitBufferにsplitStrの文字列を最大30文字コピー
strncpy(splitBuffer, splitStr, 30);
int i = 0;
char *p = NULL;
pTable[i] = splitBuffer;
/*
* splitBufferの先頭からNULL文字が現れるまで
* 区切り文字が現れたら、NULL文字を設定し文字列を区切る
* 区切り文字の次が'\0'でなければ、pTableにアドレスを設定する
*/
for(p = splitBuffer, i = 0; *p != '\0'; p++) {
if(splitChar == *p) {
*p = '\0'; // 文字列を区切る
// 次が終端文字で無ければ、ポインタを設定
if(*(p+1) != '\0') {
pTable[++i] = p+1;
}
}
}
return pTable;
}
') {
pTable[++i] = p+1;
}
}
}
return pTable;
}
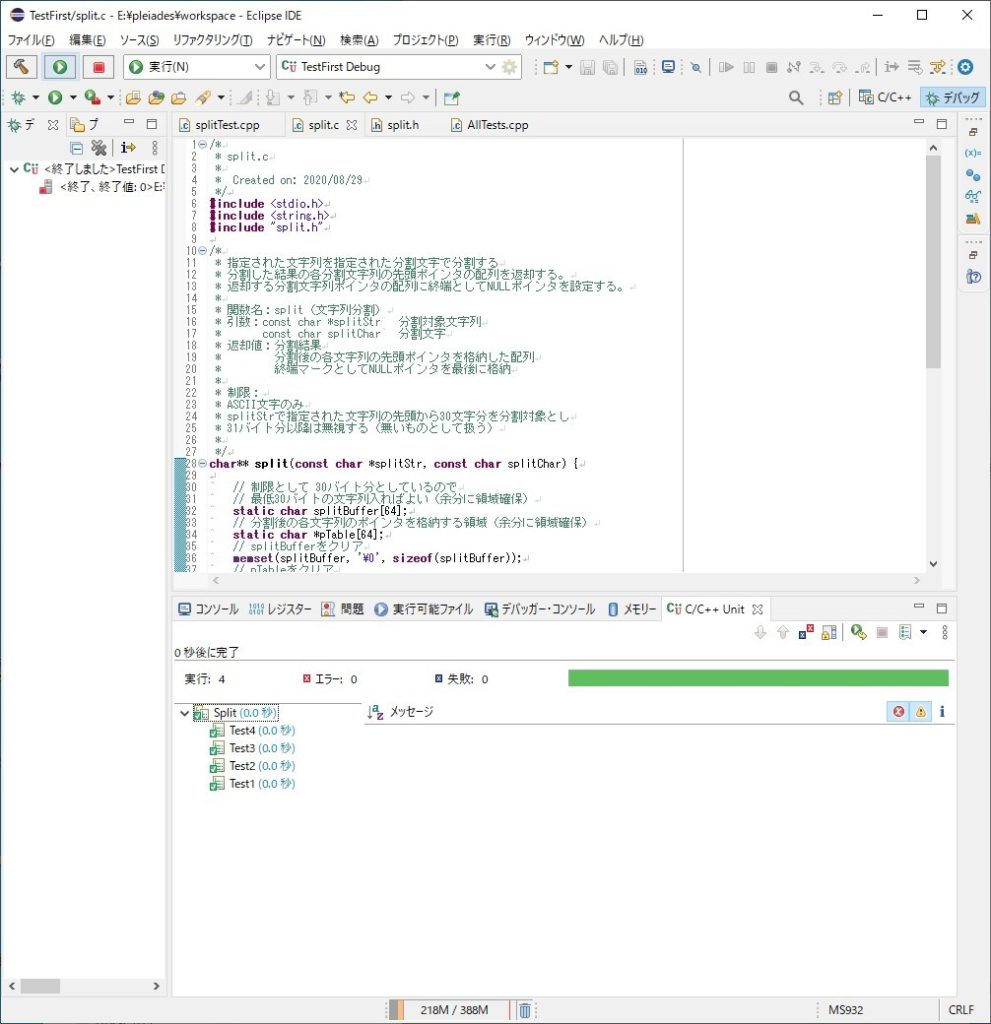
テスト結果は、以下のように全て成功しています。
これで今回の開発は無事終了しました。
C言語でテストファースト開発のまとめ
当然の話しになりますが、テスト用のプログラムを作る前にどんなテストをするのかをちゃんと考えないと良いテスト用プログラムを作る事ができません。
テスト用プログラムに間違いがある状態だと、全てのテストに成功しても正しいものが出来あがらないので注意してテストを作る必要があります。
そのため、テストプログラムの方はソースを見ただけで簡単にテストの結果が正しいかどうか確かめられるようにプログラムを作成する必要があります。
今回の場合だと、分割対象文字列と分割文字に何を指定して、結果を何と比較しているのかが、テストプログラムに直接記述しているので一目瞭然になっていると思います。
以上、【C言語】Eclipseでテストファーストに挑戦してみよう!でした。

